1. Write a note on fragmentation. Its advantages and disadvantages.
Note
A file or a table is broken down into smaller parts/sections called fragments. and those fragments are stored at different locations. A table can be fragmented horizontally (row-wise) or vertically (column-wise). Hence we have two major types of fragmentations horizontal and vertical. Different fragmentations of a table are placed at different locations.
Adv:
- The basic objective of fragmentation and placement at different places is to maximize the local access and to reduce the remote access since the later causes cost and delay.
- The concept of fragmentation should be kept hidden from the user.
- Increases the level of concurrency
- System throughput
- Localization of Data and Local Autonomy
- Distribution of data allows fast access of data due to localization
- Parallel execution of queries
Efficiency:
Data is stored close to where it is most frequently used. In addition, data that is ,not needed by' local applications is not stored.
Parallelism:
With fragments as the unit of distribution, a transaction can be divided into several sub queries that operate on fragments. This should increase the degree of concurrency, or parallelism, in the system, thereby allowing transactions that can do so safely to execute in parallel.
Dis Adv:
- Difficult to manage in case of non-exclusive Fragmentation (replication)
- Maintenance of Integrity constraints.
- Increased time/NW cost of centralized access
- Increased chances of failure
- Increased failure damage
Security:
Fragmentation has two primary disadvantages, which we have mentioned previously:
Performance:
The performance of global application that requires data from several fragments located at different sites may be slower.
Integrity:
Integrity control may be more difficult if data and functional dependencies are fragmented and located at different sites.
Data is stored close to where it is most frequently used. In addition, data that is ,not needed by' local applications is not stored.
Parallelism:
With fragments as the unit of distribution, a transaction can be divided into several sub queries that operate on fragments. This should increase the degree of concurrency, or parallelism, in the system, thereby allowing transactions that can do so safely to execute in parallel.
1.1 Vertical and horizontal fragmentation ?


1.2 Rules for correctness.

1.3.1 If fragments can change DDBMS semantic's ?
1.3.2 Write a note on completeness and reconstruction of VF ?lec: 13 - 20
Explained in 1.21.4 How can we verify the properties of completeness and reconstruction of a vertical fragmentation?(5)

1.5 How/What completeness of horizontal fragmentation is verified ?
Completeness
- The completeness of a PHF is based on the selection predicates used.
- The selection predicates are complete;
- the resulting fragmentation is guaranteed to be complete as well.
- Since the basis of fragmentation algorithm is a
- set of complete and minimal predicates,
- Pr’, completeness is guaranteed as long as no mistakes are made in defining Pr’.
- The completeness of DHF is more difficult to define.
- The difficulty is due to the fact that the predicate determining the fragmentation involves two relations.
- let R be the member relation of a link whose owner is relation S,
- which is fragmented as Fs = {S1, S2, ….., Sn}.
- Let A be the join attribute between R and S then for each tuple t of R, there should be a tuple t’ o S such that t[A] = t’[A]
Reconstruction
Reconstruction of a global relation from its fragments is performed by union operator in both
primary and derived horizontal fragmentation.
Thus for a relation R with fragmentation FR = {R1, R2, …, Rn}
R = U Ri, a'Ri FR
Disjointness
It is easier to establish disjointness of fragmentation for primary than for derived horizontal
fragmentation.
- Disjointness is guaranteed as long as the
- minterm predicates determining the fragmentation are mutually exclusive.
- In DHF, disjointness can be guaranteed if the join graph is simple.
- If it is not simple, it is necessary to investigate actual tuple values.
- The completeness of a PHF is based on the selection predicates used.
- The selection predicates are complete;
- the resulting fragmentation is guaranteed to be complete as well.
- Since the basis of fragmentation algorithm is a
- set of complete and minimal predicates,
- Pr’, completeness is guaranteed as long as no mistakes are made in defining Pr’.
- The completeness of DHF is more difficult to define.
- The difficulty is due to the fact that the predicate determining the fragmentation involves two relations.
- let R be the member relation of a link whose owner is relation S,
- which is fragmented as Fs = {S1, S2, ….., Sn}.
- Let A be the join attribute between R and S then for each tuple t of R, there should be a tuple t’ o S such that t[A] = t’[A]
Thus for a relation R with fragmentation FR = {R1, R2, …, Rn}
- Disjointness is guaranteed as long as the
- minterm predicates determining the fragmentation are mutually exclusive.
- In DHF, disjointness can be guaranteed if the join graph is simple.
- If it is not simple, it is necessary to investigate actual tuple values.
1.6 About Horizontal Fragmentation, Owner and member relation
Explained in 1.7
1.7 Differentiate between VF and HF OR(PHF or VHF)
Primary Horizontal Fragmentation is a table fragmentation technique in which we fragment a single table and this fragmentation is row-wise and using a set of simple conditions.
- Given: A relation R, the set of simple predicates Pr
- Output: The set of fragments of R = {R1, R2,…,Rw} which obey the fragmentation rules.
- Preliminaries :
- Pr should be complete
- Pr should be minimal


Given a relation R, its horizontal fragments are
An important aspect of simple predicates is their completeness, another is their minimality. A set of
simple predicates Pr is said to be complete if and only if there is an equal probability of access
by every application to any tuple belonging to any minterm fragment that is defined according to
Pr.

DHF - Derived Horizontal Fragmentation
It is defined on a member relation of a link according to a selection operation specified on
its owner. Two important points are:
- Each link between owner and member is defined as an equi-join.
- Equi-join can be implemented by means of semi-joins
So we are interested in defining the partitions of member based on fragmentation of its owner,
but want to see attributes only from member





The two fragments PAY1 and PAY2 of PAY and EMP1 and EMP2 of EMP are defined
as follows:
- PAY1 = ... SAL >30000 (PAY)
- PAY2 = ... SAL ≤ 30000 (PAY)
- EMP1 = EMP ⋉ PAY1
- EMP2 = EMP ⋉ PAY2
The result of this fragmentation is depicted in figure 2.

3. Write a note on need for distributed database. Why it's more beneficial? What is meant by optimality?
Two Most reasons are:- large no of users.
- Users are physically spread across large geographical area.
4. What are complete predicates? Minterm predicates?
Completeness of Simple Predicates
A set of simple predicates Pr is said to be complete if and only if
- The accesses to the tuples of the minterm fragments defined on Pr requires:-
- That two tuples of the same minterm fragment have
- the same probability of being accessed by any application.
- It is conjunction of the simple predicates.
- It is always possible to transform a Boolean expression into conjunction normal form
- The use of minterm predicates in the design algorithms does not cause any loss of generality.
Pr = {pr1, pr2, …, pm}for a relation R, the set of minterm predicates M is defined as M =
{m1, m2, ……, mz}

Consider relation PAY(title, sal). The following are some of the possible simple predicates that
can be defined on PAY.

- If a predicate influences how fragmentation is performed,
- (i.e., causes a fragment f to be further fragmented into, say, fi and fj)
- then there should be at least one application that accesses fi and fj differently.
- In other words, the simple predicate should be relevant in determining a fragmentation.
- If all the predicates of a set Pr are relevant, then Pr is minimal.
Example :
Pr ={LOC=“Montreal”,LOC=“New York”, LOC=“Paris”, BUDGET≤200000,BUDGET>200000}
is minimal (in addition to being complete). However,
if we add PNAME = “Instrumentation” then Pr is not minimal.
5. Write the formula to calculate affinity matrix? - lec 18
their surrounding elements.

5.1 Draw CA(clustered affinity ) along with Affinity matrix ( lect 19 )
5.2 To make affinity matrix. Describe the contribution of moving attribute A4 between A1 and A2.
5.3 Affinity matrix for given queries, and contribution of moving column 3 between column 1 and column 2.
5.1 to 5.3 explained in 5.45.4 Attribute Usage Matrix for given queries
PROJ(jNo, jName, budget, loc)
q2: SELEC JNAME, BUDGET FROM PROJ
q3: SELECT JNAME FROM PROJ WHERELOC=Value
q4: SELECTSUM(BUDGET) FROM PROJ WHERE LOC=Value
Let A1= jNo, A2= jName, A3= budget, A4= loc
If Attribute exist in query add 1 against the query otherwise, 0.
Attribute affinity matrix
- aff(Ai,Aj) = ∑ ∑ refl(qk) accl(qk)
- Where refl(qk) is no of accesses to attributes (Ai,Aj) for each execution of qk at site Sl
- and accl(qk) is application access frequency measures from Si
- acc1(q1) = 15, acc2(q1) = 20, acc3(q1) = 10
- acc1(q2) = 5, acc2(q2) = 0, acc3(q2) = 0
- acc1(q3) = 25, acc2(q3) = 25, acc3(q3) = 25
- acc1(q4) = 3, acc2(q4) = 0, acc3(q4) = 0
suppose refl(qk) = 1

It will measure between only two attributes at a time.
Aff value will be calculated only if any query access both attributes at a time.
F:eg
aff(A3, A4)
= ∑k = 4 ∑l =1..3 refl(qk)accl(qk) - here 4means query 4 where both have 1 in left matrix
= 3 *1 + 0 + 0 = 3 - here add all values of query 4 aftr * with refl(qk) value 1
aff(A1, A2) = 0, Since no qi accesses them both
aff(A2, A2) = 5 * 1 + 0 + 0 = 5
25 * 1 + 25 *1 + 25 * 1 = 75 + 5 = 80
Bond Energy Algorithm
Algo
-Begin
CA (•, 1) ← AA (•, 1)
CA (•, 2) ← AA (•, 2)
Index ← 3
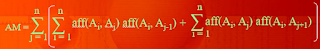


Ordering (2-3-4)

Algo
- Input AA
- Output CA
-Begin
CA (•, 1) ← AA (•, 1)
CA (•, 2) ← AA (•, 2)
Index ← 3
--While index ≤ n do - n as no of columns
Begin
For (I=1 I=<index –1 i++)
---do
calculate cont(Ai-1, Aindex, Ai)
---end-for
Calculate cont(Aindex-1, Aindex, Aindex+1)
Loc ← placement given by maximum cont value
For (j=index j<=loc-1 i--)
---do
CA (•, j) ← AA (•, j-1)
---end-for
CA (•, loc) ← AA (•, index)
Index ← index + 1
--End-while
Order the rows according to relative order of columns
-End {BEA}


- Ordering (0-3-1) – means A3 on left of A1
- Ordering (1-3-2) – means A3 in between A1 and A2
- Ordering (2-3-4) – means A3 on right of A2
Ordering (0-3-1)
cont (A0, A3, A1) = 2 bond(A0, A3) + 2 bond(A3, A1) – 2bond(A0, A1)
- bond(A0, A3) = 0
- bond(A0, A1) = 0
- bond(A3, A1) = ∑(z=1 to 4)aff(Az, A3)aff(Az, A1)
- =
- aff(A1, A3)aff(A1, A1) + aff(A2, A3) aff(A2, A1) + aff(A3, A3)aff(A3, A1) + aff(A4,A3)aff(A4, A1)
- = 45 * 45 + 5 * 0 + 53 * 45 + 3 * 0 = 4410
- Thus
cont(A0, A3, A1) = 2 bond(A0, A3) + 2 bond(A3, A1) - 2bond(A0, A1)
- = 2 * 0 + 2 * 4410 – 2 * 0
- = 8820
Ordering (1-3-2)
cont (A1, A3, A2) = 2 bond(A1, A3) + 2 bond(A3, A2) - 2bond(A1, A2)
- bond(A1, A3) = bond(A3, A1) = 4410
- bond(A3, A2) =0+400+265+225= 890
- bond(A1, A2) =0+0+45*5= 225
- = 8820 + 1780 – 450
- = 10150
cont (A2, A3, A4) = 2 bond(A2, A3) + 2 bond(A3, A4) - 2bond(A2, A4) bond(A2, A3) = 890
bond(A3, A4) = 0
bond(A2, A4) = 0
cont (A2, A3, A4) = 2 * 890 + 0 + 0 = 1780
- Ordering (0-3-1) = 8820
- Ordering (1-3-2) = 10150
- Ordering (2-3-4) = 1780
Compute the contribution by placing 4th attribute at different places in CA, We need to work out
- Ordering (0-4-1)
- Ordering (1-4-3)
- Ordering (3-4-2)
- Ordering (2-4-5)

6. Explain (A1, D2, H1) (A1, D0, H1) architectures of DBMS.
Autonomy (0 1 2)- Tight hydrogenation
- semi autonomous
- total isolation
Distribution
- 0 No distribution
- 1 client/server
- 2 Peer to Peer
Heterogeneity
- 0 homogeneous
- 1 Heterogeneous
(A1,D2,H1)
A1(semi autonomous)
D2 (Peer to Peer)
H1 (Heterogeneity)
(A1,D0,H1)
A1 (semi
autonomous)
D0 (No
distribution)
H1
(Heterogeneity)
7. What is autonomy? What are its types? How it's classified?
AutonomyDegree to which member databases can operate independently Autonomy is how much independently the member databases perform their functionality or make their decision.
Design Autonomy
Freedom for designer to make decision related to design, e.g., which data model he wants to design the database in, which DBMS he thinks is suitable for the organization. It may also include the decisions like machine to buy or operating system to be based on.
Communication Autonomy
What part of data we want to share. It depends on the nature of bond/coupling between member databases. If they are independent or are different organization, then obviously they own their data and can decide independently. However, if there is some strong bond between the member databases or they belong to the same organization then the member DBA does not have much autonomy and it is decided centrally somewhere what to be contributed from a member database and what not.
Execution Autonomy
Component databases the authority for when to share the data when to shut down etc. Again in case of same organization, the rules are formulated at the head office level and all member databases have to follow that, otherwise they are autonomous to make this decision.
Classification
One possible classification of DDBMSs follows:
Tight integration
- All users get a single common view with a feeling that there are no component databases.
- Component database are present and they relate their data and at certain time they share their data to form a common view.
- All the systems are stand alone.
8. How we remove transitive dependency?
Transitive Dependency: If for a relation R, we have FDs a àb and b à c then it means that a à c, where b and c both are non-key attributes.9. Describe software component of replication? ( lect 21 )
Software components used in replication are of 4 types:- Snapshot
- Merge
- Distribution
- Log Reader.
- Runs at least once in all reps.
- Meld changes from different servers made since last snapshot.
- Performs different activities, mainly distributes publication to subscribers.
- Used in transactional rep, reads log files of all servers involved.
9.1 Name the software used for replication (5)
SQL Server multiple instances used as publish-subscribe model. F eg: Personal Edition of SQL Server.
Additionally software used SS Agents and its component:
- Snapshot
- Merge
- Distribution
- Log Reader.
9.2 Discuss the disadvantages of replication ?
Storing a separate copy of database at each of two or three sites is called replicationAdvantages
- Reliability.
- Fast response.
- May avoid complicated distributed transaction integrity routines (if replicated data is refreshed at scheduled intervals.)
- De-couples nodes (transactions proceed even if some nodes are down.)
- Reduced network traffic at prime time (if updates can be delayed.)
Disadvantages
- Additional requirements for storage space.
- Additional time for update operations.
- Complexity and cost of updating.
- Integrity exposure of getting incorrect data if replicated data is not updated simultaneously.
- Therefore, better when used for non-volatile data.
9.3 Describe SQL Server tools involves In replication.
- Personal Edition of SQL Server.
- Replication uses a publish-subscribe model for distributing data.
- Publication is group of related data and objects to replicate together.
- Publisher is a server that is the source of data to be replicated.
- Subscriber is a server that receives the data replicated by the publisher.
- Subscriber defines a subscription to a particular publication.
- Distributor is a server that performs various tasks when moving articles from Publishers to Subscribers.
9.4 Differentiate between fully and partially databases
Same as 9.5
9.5 Differentiate b/w Non-Replicated Databases and Partitioned Database (5 marks)
sites, and there is only one copy of any fragment on the network.
- In case of replication, The database exists entirely at each site (fully replicated database) or
- Fragments are distributed to the sites in such a way that copies of a fragment may reside in multiple sites (partially replicated database)
10. Why distributed database system’s performance is better than centralized database system.(5)
Centralized database System:Data management is carried on a single centralized system. However this data is accessed from different machine (clients). All machines are connected with each other through a communication link (network).In the centralized system the data is store and manage on the server,the data is associated with a single site, this site is basically the Server, rest of the machines are accessing data from the Server.
The Distributed Database System:
The data is managed/manipulated at multiple sites in a DDBS. There are many different architectures of a DDBS. There are a number of local DBMSs called local nodes. Each local node works independently serving multiple users that are connected to it, these users are called local nodes. At the same time, the local nodes are connected with each other. A layer is superimposed on top of all these connected local DBMSs and that layer is the DDBMS.
Improved Performance
As the data is located near the site of 'greatest demand', and given the inherent parallelism of distributed DBMSs, speed of database access may be better than that achievable from a remote centralized database. Furthermore, since each site handles only a part of the entire database, there may not be the same contention for CPU and I/O services as characterized by a centralized DBMS.
11. Key differences between LAN and WAN
LAN (Local Area Network):- Small geographical area
- High Band width
- Low latency
- it is optimized to process a very high volume of data messages with minimal delay (latency)
- Used inter-city country or even continental
- gives low bandwidth high latency. (Delay) more delay comparative to other Networks.
- Can be Broadcast and Point to Point.
12 DDBMS Components their working and Interfacing
Figure 2: Components of a Distributed DBMS (65)
- User processor and Data processor are two major components of distributed DBMS.
- One component handles the interaction with users and other deals with the storage.
- The user interface handler is responsible for interpreting user commands and formatting the result data as it is sent to the user.
- The semantic data controller uses the integrity constraints and authorizations that are defined as part of the global conceptual schema to check if the user query can be processed.
- The global query optimizer and decomposer determines an execution strategy to minimize a cost function and translates the global queries into local ones using global and local conceptual schema as well as global directory. The global query optimizer is responsible for generating the best strategy to execute distributed join operations.
- The distributed execution monitor coordinates the distributed execution of the user request. The execution monitor is also called the distributed transaction manager.
- The local query optimizer, which actually acts as the access path selector, is responsible for choosing the best path to access any data item.
- The local recovery manager is responsible for making sure that the local database remains consistent even when failures occur.
- The run-time support processor physically accesses the database according to the physical commands in the schedule generated by the query optimizer. The run-time support processor is the interface to the operating system and contains the database buffer manager which is responsible for main memory buffers and data accesses.
12.2 Independence of Distributed Database
- Local Independence
- Fragmentation Independence
- Replication Independence
- Hardware Independence
- Operating System Independence
- Network independence
- DBMS Independence
Users should not have to know where data is physically stored, but logically they percieved as the data were all stored at their own local site.
2. Fragmentation Independence (Fragmentation Transparency)
Fragmentation independence refers to the ability of end users to store logically related information at different physical locations.
The user sees only one single logical database. Data fragmentation is transparent to the user. The user does not need to know the name of the database fragment in order to retrieve them.
Note: A system supports data fragmentation if a given Table can be divided up into pieces or fragments for physical storage purposes.
Note: Fragmentation is desirable for performance reasons: Data can be stored at location where it is most frequently used, so that most operations are local and network traffic is reduced.
3. Replication Independence (Replication Transparency)
The user sees only one single logical database.
The DDBMS transparently access the database fragment.
The DDBMS manages all fragments transparently to the user.
Note: the existence of fragment copies can enhance data availability and response time, data copies can help to reduce communication and total query costs.
4. Hardware Independence
The system must run the same DBMS on different hardware platforms.
5. Operating System Independence
The system must run the same DBMS on different operating system Platforms including different operating systems on the same hardware and have (e.g.) a UNIX version and an NT version all participate in the same distributed system.
6. Network independence
The system must support a variety disparate communication networks.
7. DBMS Independence
The system must support any vendor's database product.
The DBMS instances at different sites all support the same interface - they do not necessarily all have to be copies of the same DBMS software.
The ideal distributed system should be heterogeneous (multiple forms) and should provide DBMS independence.
12.3 Write ways of user access data from DDBMS?
In a DDBS environment, three types of accesses are involved:- Local access: the access by the users connected to a site and accessing the data from the same site.
- Remote access: a user connected to a site, lets say site 1, and accessing the data from site 2.
- Global access: no matter from where ever the access is made, data will be displayed after being collected from all locations.
12.4 Inputs needs for distributed database?
- Data requirements or querry
- How the data will be gether
12.5 How the distributed databases are connected?
A distributed database system allows applications to access data from local and remote databases. In a homogenous distributed database system, each database is an Oracle Database. In a heterogeneous distributed database system, at least one of the databases is not an Oracle Database. Distributed databases use a client/server architecture to process information requests.12.6 Global schema importance in DDBS.
- The global conceptual schema is a logical description of the whole database.
- The conceptual level of the ANSI-SPARC architecture
- It contains definitions of entities, relationships, constraints, security and integrity information.
- It provides physical data independence from the distributed environment.
- Whereas, the global external schemas provide logical data independence.
13. Star and bus topology
13.1 Differentiate between Bus and ring Topology
Look at 14
14. classification criteria of computer network.
The classification based on the transmission mode is
- Point to point (unicast)
- Broadcast (multi-point)
Point to point
One or more links between sender and receiver Link may be direct or through switching.
Broadcast
Common channel utilized by all nodes.
Message received by all ownership checked.
Generally radio or satellite based or microwave.
14.1 classify the computer networks?
Computer network A computer network is a system for communication between two are more computer, where computers are Interconnected and Autonomous. Computers are called nodes, sites, host. Other equipment at nodes. i.e. they may or may not be computers. Equipment connected via links and channels .
Types of Network:
we can classify networks on
different bases, following are the criteria according to which we can classify
the networks: Interconnection structure ------- topology. Transmission mode.
Geographical distribution. Based on the interconnection structure there are
following categories of the networks 1)
Star 2) Bus 3) Ring 4) Mesh
Star topology: Many home networks use the star topology. A star
network features a central connection point called a "hub" that may
be an actual hub or a switch. Devices typically connect to the hub with
Unshielded Twisted Pair (UTP) Ethernet. Compared to the bus topology, a star
network generally requires more cable, but a failure in any star network cable
will only take down one computer's network access and not the entire LAN. (If
the hub fails, however, the entire network also fails.)
Ring network: In a ring network, every device has exactly two
neighbors for communication purposes. All messages travel through a ring in the
same direction (effectively either "clockwise" or
"counterclockwise"). A failure in any cable or device breaks the loop
and can take down the entire network. Rings are found in some office buildings
or school campuses.
Bus network: Bus networks use a common backbone to connect all
devices. A single cable, the backbone functions as a shared communication
medium, that devices attach or tap into with an interface connector. A device
wanting to communicate with another device on the network sends a broadcast
message onto the wire that all other devices see, but only the intended
recipient actually accepts and processes the message.
Meshed network: Mesh topologies involve the concept of routes.
Unlike each of the previous topologies, messages sent on a mesh network can
take any of several possible paths from source to destination. (Recall that in
a ring, although two cable paths exist, messages can only travel in one
direction.) Some WANs, like the Internet, employ mesh routing.
15. what is Primary and secondary key n composite n super key difference?
Super Key: An attribute or set of attributes whose value can be used to uniquely identify each record/tuple in a relation is super key. For example, in the EMP table ENo is a super key since its value identifies each tuple uniquely. However, ENo, EName both jointly are also the super key, likewise other combinations of attributes with ENo are all super keys.A composite key is a combination of two or more columns in a table that can be used to uniquely identify each row in the table when the columns are combined uniqueness is guaranteed, but when it taken individually it does not guarantee uniqueness.
Candidate Key: is the minimal super key, that is a super key whose no proper subset itself is a super key. Like in the above example ENo is a super key and a candidate as well. However, the ENo, EName jointly is super key not the candidate key as it has a proper subset (ENo) that is a super key.
Primary key: The successful/selected candidate key is called the primary key, remaining candidate keys are called alternate keys.
Secondary key is the attribute(s) that are used to access data from the relation but whose value is not necessarily unique, like EName.
16. What is the purpose of integrity rules? How they are enforced on the database?(5 marks)
Integrity rules are applied on data to maintain the consistency of the database, or to make it sure that the data in the database follows the business rules. There are 2 types of integrity rulesStructural Integrity Constraints
- Depends on data storage
- Declared as part of data model
- Stored as part of schema
- Enforced by DBMS itself
- These are the rules/ semantics of the business
- Depends on business
- Enforced through application program
17. components of relational data model.
A data model that is based on the concept of relation or table. The concept of relation has been taken from the mathematical relation. In the databases, the same relation represented in a two dimensional way is called table, so relation or table represent the same thing. The RDM has got three components:
- Structure à support for storage of data and RDM supports only a single structure and that is a relation or a table.
- Manipulation language à The language to access and manipulate data from the database. The SQL (Structured Query Language) has been accepted as the standard language for RDM. The SQL is based on relational algebra and relational calculus.
- Support for integrity constraints: The RDM support two major integrity constraints such that they have become a part of the data model itself. It means that any DBMS that is base on the RDM must support these two constraints and they are
- Entity integrity constraint
- Referential integrity constraint